The subject pdf and crawl or indexing with SharePoint is really huge. It starts with the iFilter PDF which needs to be installed on SharePoint 2010 and which is by default included in SP2013. But it is limited. It makes fulltext indices but it does not indexing the extended metadata from PDFs like keywords or subject (Thema).
If you would like to know how to get those fields also indexed by SharePoint read on. I try to explain what i did to achieve this. In my customer scenario we are crawling a lot of pdf’s from fileshare. In order to be able to search for a word which is in the subject or keyword section of this pdf we configured the search schema with its managed metadata.
At first let us have a look which properties are meant to be indexed:
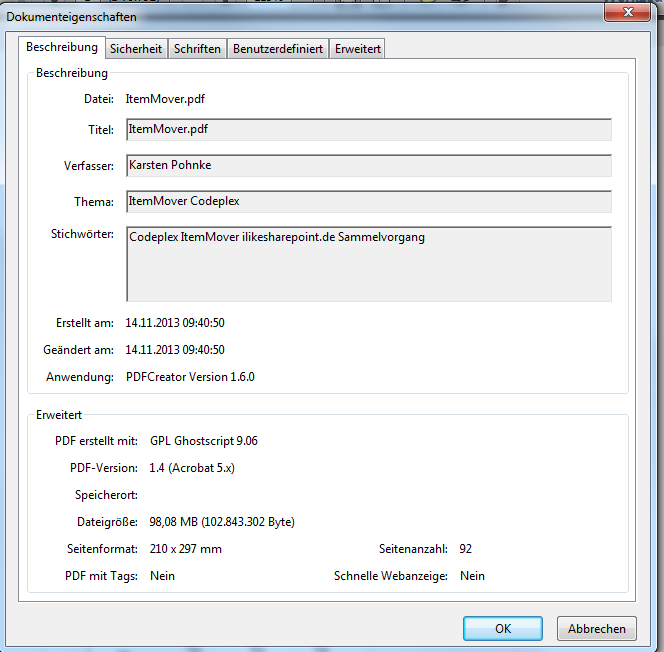
As you can see, the “Thema” field and the “Stichwörter” field (keywords) are those we want to be indexed.
Ok, well these properties have to be mapped, but to what? Where can i find this information to map the correctly?I found this really nice post from Matthew McDermott in which he recommends to use iFilterView software to examine the properties. I downloaded this software and opened my pdf and could see this:
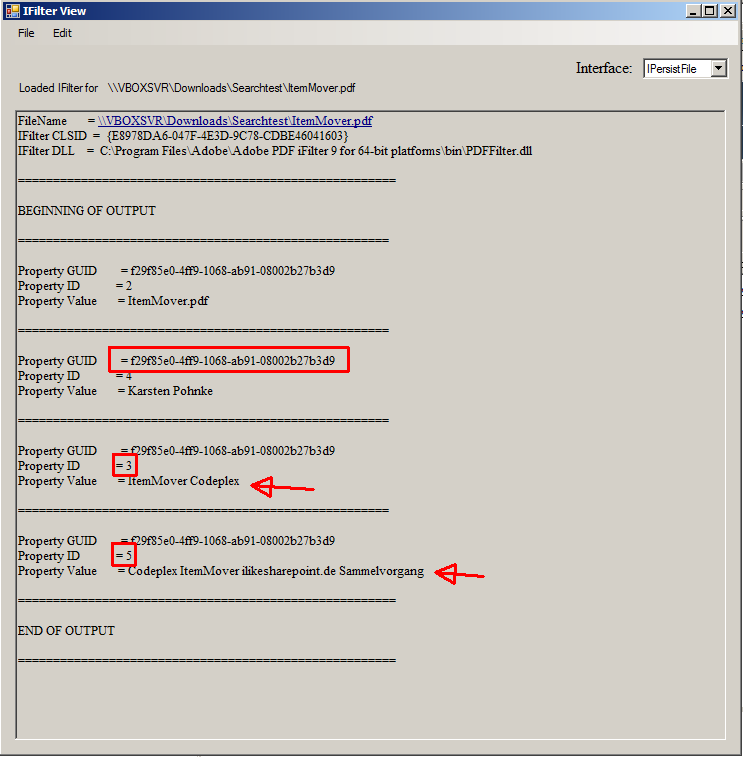
Well, Matthew explained it already. The Property Guid can be also find in some of the crawled metadata. The property ID is also findable in the crawled metadata. So what we need to do right now, is to find those metadata and map it correctly.
Part 1: Map “Thema”
At first we create a new managed property and call it PDFThema. I found the property guid in one of the crawled properties called office.
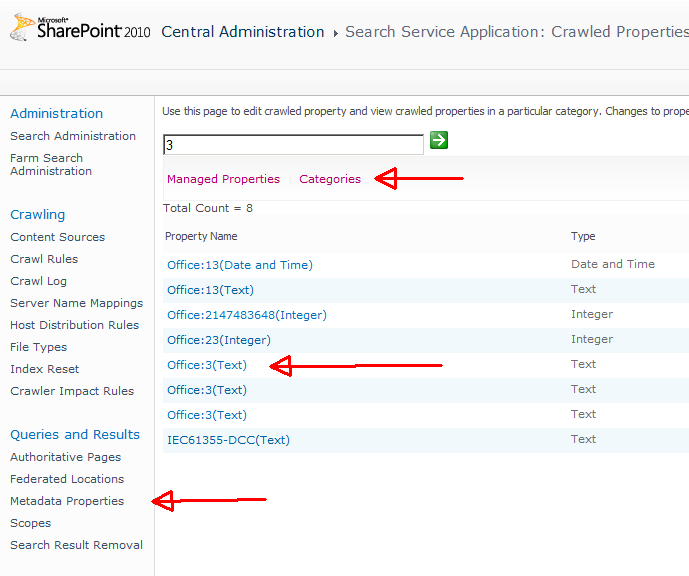
And it was called Office:3 so i mapped this crawled property to my managed metadata.
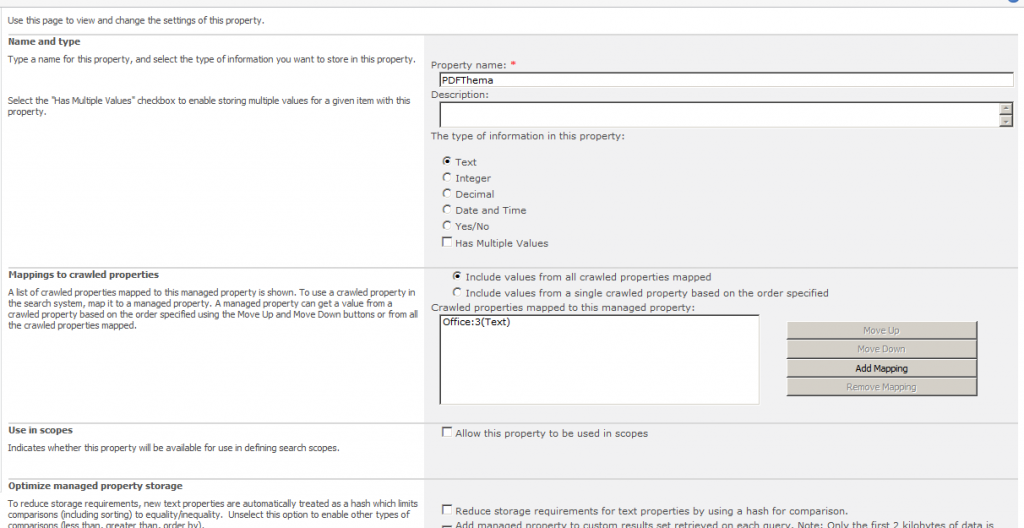
I configured it in SP2013 to be searchable, retrievable and queryable.
That’s it for the PDFThema property.
Part 2: Map Keywords
I created a new managed metadata called PDFKeywords and mapped the crawled metadata Office:5 to it (in the screenshot you see it 2 times, but only one with the right property guid is enough).
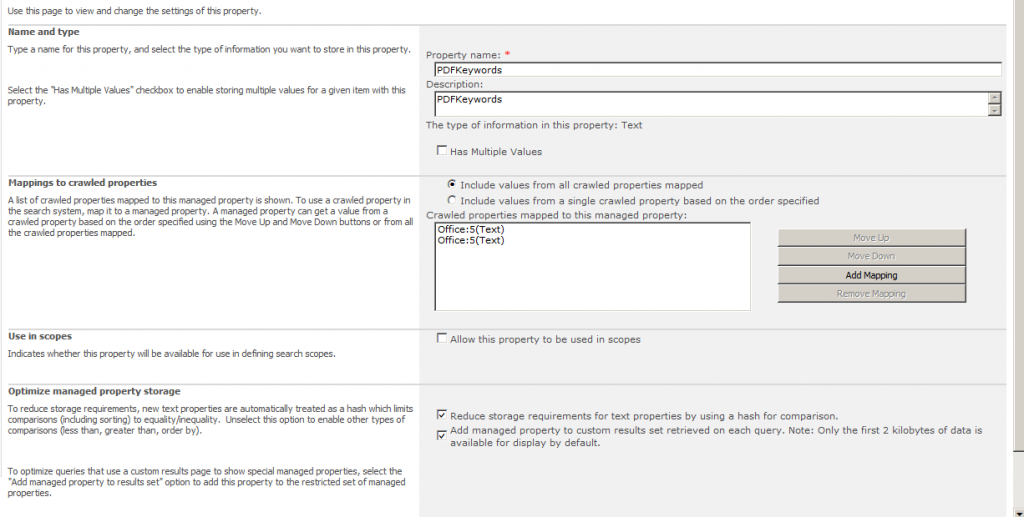
After that i went to my crawled properties and clicked on the selected Office:5 metadata and it displays this screen:

As you can see it is also mapped to DocKeywords. Really interesting.
Now we are almost done. At last step you have to start a full crawl on your content source and after it’s done you should be able to search for Itemmover or codeplex and the search result should contain the pdf.
Hope you liked it and it maybe helps you at your pdf-searching 🙂
..:: I LIKE SHAREPOINT ::..
Leave a Reply
You must be logged in to post a comment.